Security Problem
As for HDFS, which is configured along with Hadoop, the 'dfs.namenode.http-address' parameter in hdfs-site.xml specifies an URL which is used to monitoring HDFS:<property> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>k1201.hide.cn:8020</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>k1202.hide.cn:8020</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>k1201.hide.cn:50070</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>k1202.hide.cn:50070</value> </property>
After HDFS service is on, the HDFS monitoring webpage just looks like below:
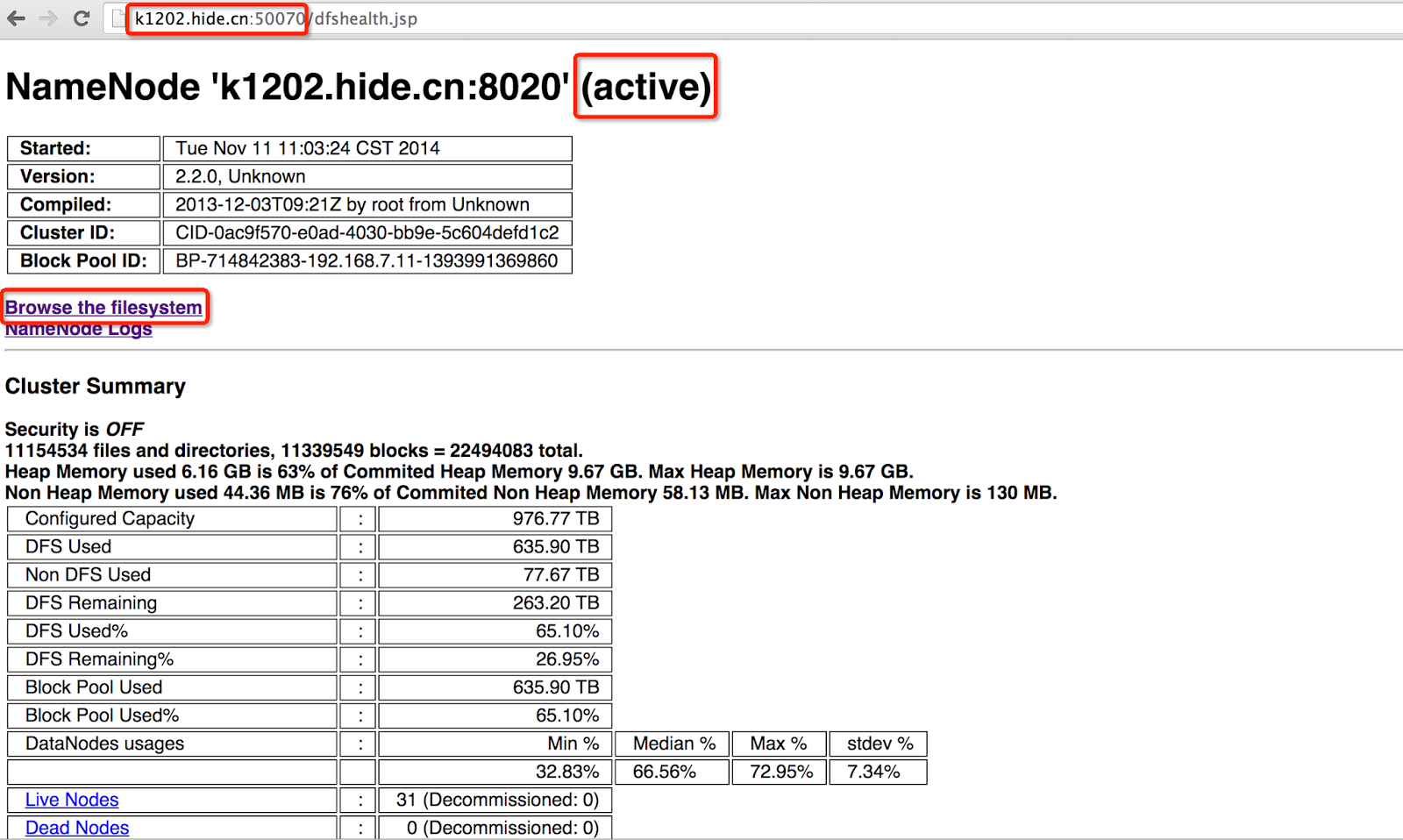
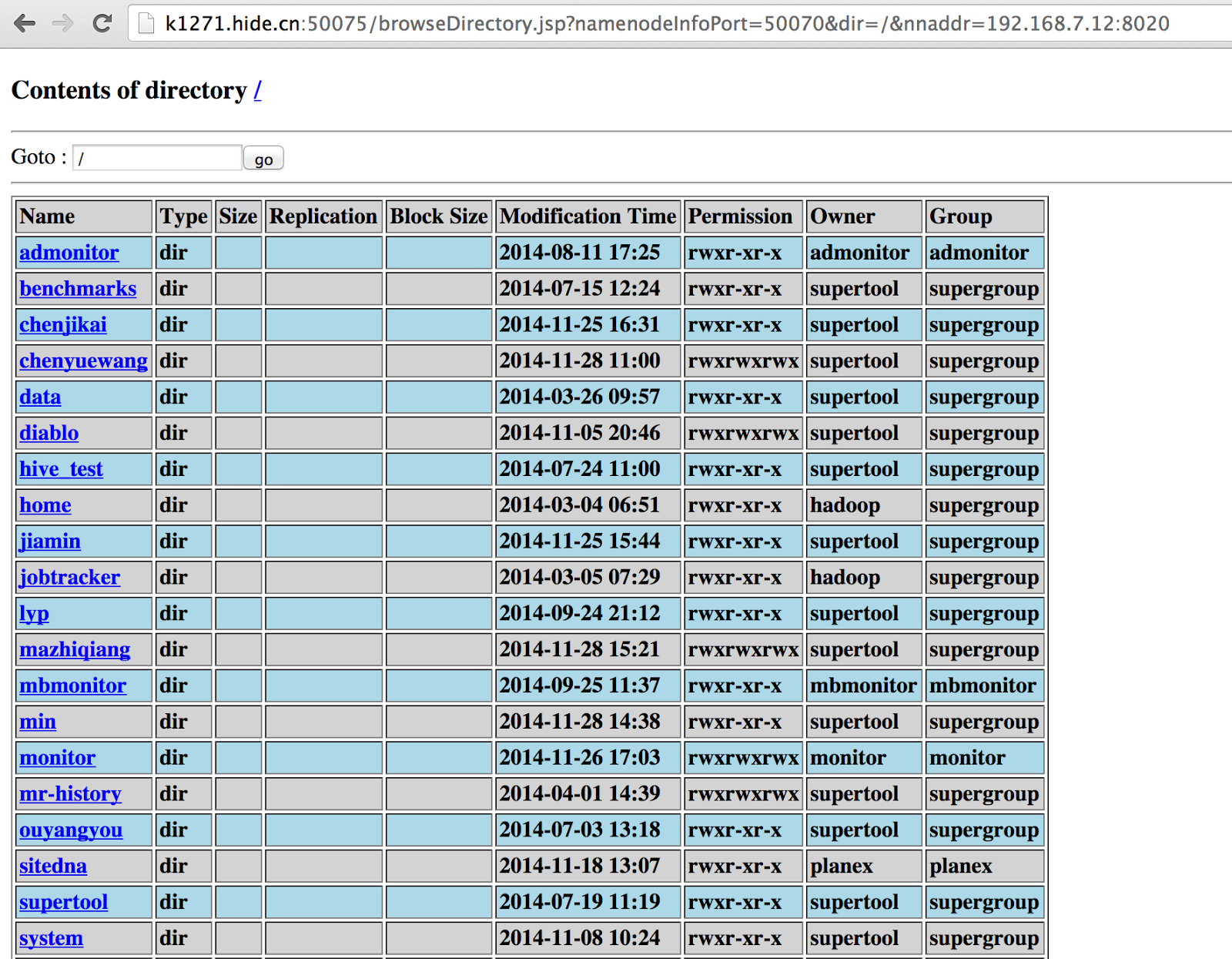
If clicking 'Browse the filesystem' , we could explore and download ALL DATA stored in HDFS, which is virtually not what we want.
Configuration For Iptables
Firstly, erase all current iptables rules should iptbales is on. The reason that we have to explicitly state INPUT, FORWARD, OUTPUT to ACCEPT is that no packet can pass into that machine after we execute flush if one of them is set default to DROP./sbin/iptables --policy INPUT ACCEPT /sbin/iptables --policy FORWARD ACCEPT /sbin/iptables --policy OUTPUT ACCEPT /sbin/iptables --flush
The final target of our settings in iptables is to block all kinds of TCP connections (apart from SSH) from external IP address to nodes in Hadoop cluster, whereas the reverse direction is allowed. In the meantime, connections among nodes in Hadoop cluster should not be restricted. Here's the command to achieve this:
iptables -L -v -n iptables -A INPUT -s 192.168.0.0/255.255.0.0 -j ACCEPT iptables -A OUTPUT -d 192.168.0.0/255.255.0.0 -j ACCEPT iptables -A INPUT -s 127.0.0.1 -j ACCEPT iptables -A OUTPUT -d 127.0.0.1 -j ACCEPT iptables -A INPUT -p tcp --dport ssh -j ACCEPT iptables -A OUTPUT -p tcp --sport ssh -j ACCEPT iptables -A INPUT -m state --state ESTABLISHED,RELATED,UNTRACKED -j ACCEPT iptables --policy INPUT DROP iptables --policy OUTPUT ACCEPT
- `-L` will show current rules set in iptables, and will start iptables provided the service is off. `-v` will show detailed packet and byte info. `-n` will disable all DNS resolution in the output results.
- The next two lines of rule will allow any packet that are from node with LAN IP 192.168.*.* going in and out.
- The fourth and fifth line of rule accepts any packet that are from localhost/127.0.0.1.
- The sixth and seventh line of rule will accept ssh connection from any source, namely LAN IP and external IP.
- The eighth line of rule will allow all TCP INPUT whose state is ESTABLISHED, RELATED or UNTRACKED, purpose of which is allowing all Hadoop nodes to start TCP connection with external IP and the external one can send back packets successfully.
- The last two lines of rule set the default policy of INPUT and OUTPUT to DROP, so as to block anything if a packet is not matched by the above rules.
After setting, run the following command again to double check whether rules have been configured successfully or not.
$ iptables -L -v -n Chain INPUT (policy DROP 199 packets, 66712 bytes) pkts bytes target prot opt in out source destination 4243K 3906M ACCEPT all -- * * 192.168.0.0/16 0.0.0.0/0 409 47240 ACCEPT all -- * * 127.0.0.1 0.0.0.0/0 0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:22 119 19947 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED,UNTRACKED Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 131 packets, 9395 bytes) pkts bytes target prot opt in out source destination 1617K 6553M ACCEPT all -- * * 0.0.0.0/0 192.168.0.0/16 409 47240 ACCEPT all -- * * 0.0.0.0/0 127.0.0.1 0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp spt:22
If all is correct, remember to make it persistent via the following command. If not, iptables will reload the persistent iptables-config file, which may be a stale version of iptables rules, at the time the machine restarts.
/sbin/iptables-save > /etc/sysconfig/iptables
From my own Mac, which is external IP of course, run the following command in order to check whether the specific port in that Hadoop node is available or not.
telnet 644v(1/2/3).hide.cn 22 #Success! telnet 644v(1/2/).hide.cn 50070 #Fail telnet 644v(1/2/3).hide.cn 50075 #Fail telnet 644v(1/2/).hide.cn 9000 #Fail # Or in a more elegant way: $ nmap -sT -sV -Pn 644v*.hide.cn Starting Nmap 6.47 ( http://nmap.org ) at 2014-12-01 10:40 HKT Nmap scan report for *.hide.cn (xx.xx.xx.xx) Host is up (0.017s latency). rDNS record for xx.xx.xx.xx: undefine.inidc.com.cn Not shown: 999 filtered ports PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 4.3 (protocol 2.0)
In the above, 50070 is set by 'dfs.namenode.http-address', 50075 is set by 'dfs.datanode.http.address', and 9000 is set by 'dfs.namenode.rpc-address'. All these parameters are configured in hdfs-site.xml.
After configuring, we SSH to a node in Hadoop cluster, executing `hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount input output` and it turns out successful.
Proxy Setting For Hadoop Cluster
After starting iptables, we are not able to access HDFS and YARN monitoring webpages from external IP anymore. The easiest way to solve this problem elegantly is to set dynamic port forwarding via `ssh`.Only two commands are required to invoke on our own PC:
netstat -an | grep 7001 ssh -D 7001 supertool@644v3.hide.cn
The purpose of first command is to check whether port 7001 has been occupied by other programs. If not, the second command will create a socks tunnel from our own PC to the node in Hadoop cluster via ssh. All packets sending to port 7001 in our PC will forward to that node in Hadoop cluster.
As for chrome, we could configure it in SwitchySharp, which is quite simple and handy, as below:
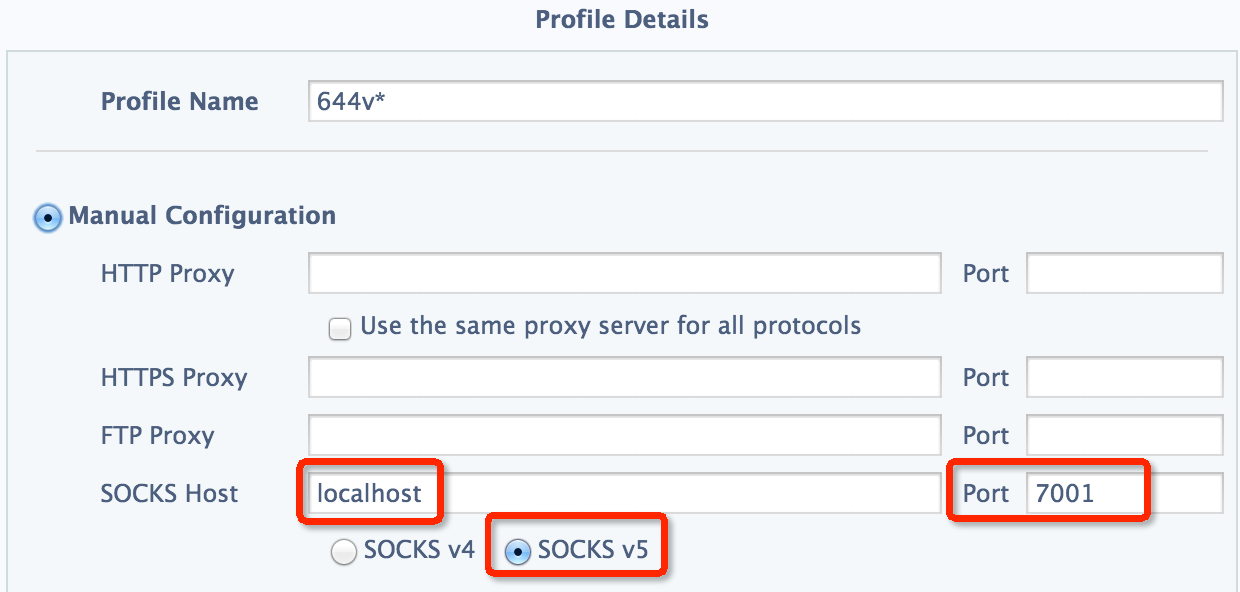
However, since the node in Hadoop cluster is not accessible to external IP, we are not capable of surfing the Internet like youtube or twitter as well as monitoring on the HDFS or YARN webpage simultaneously provided configuration of proxy is set in the above manner.
Consequently, I write a custom PAC file which looks like below:
function FindProxyForURL(url,host)
{
if(host.indexOf("hide") > -1)
return "SOCKS5 127.0.0.1:7001";
return "DIRECT";
}
In which, "hide" is the keyword of our host for HDFS and YARN monitoring webpage. If "hide" appears in the host name, use the SOCKS5 proxy, and direct connection is applied otherwise.
Finally, import this PAC file in SwitchySharp:
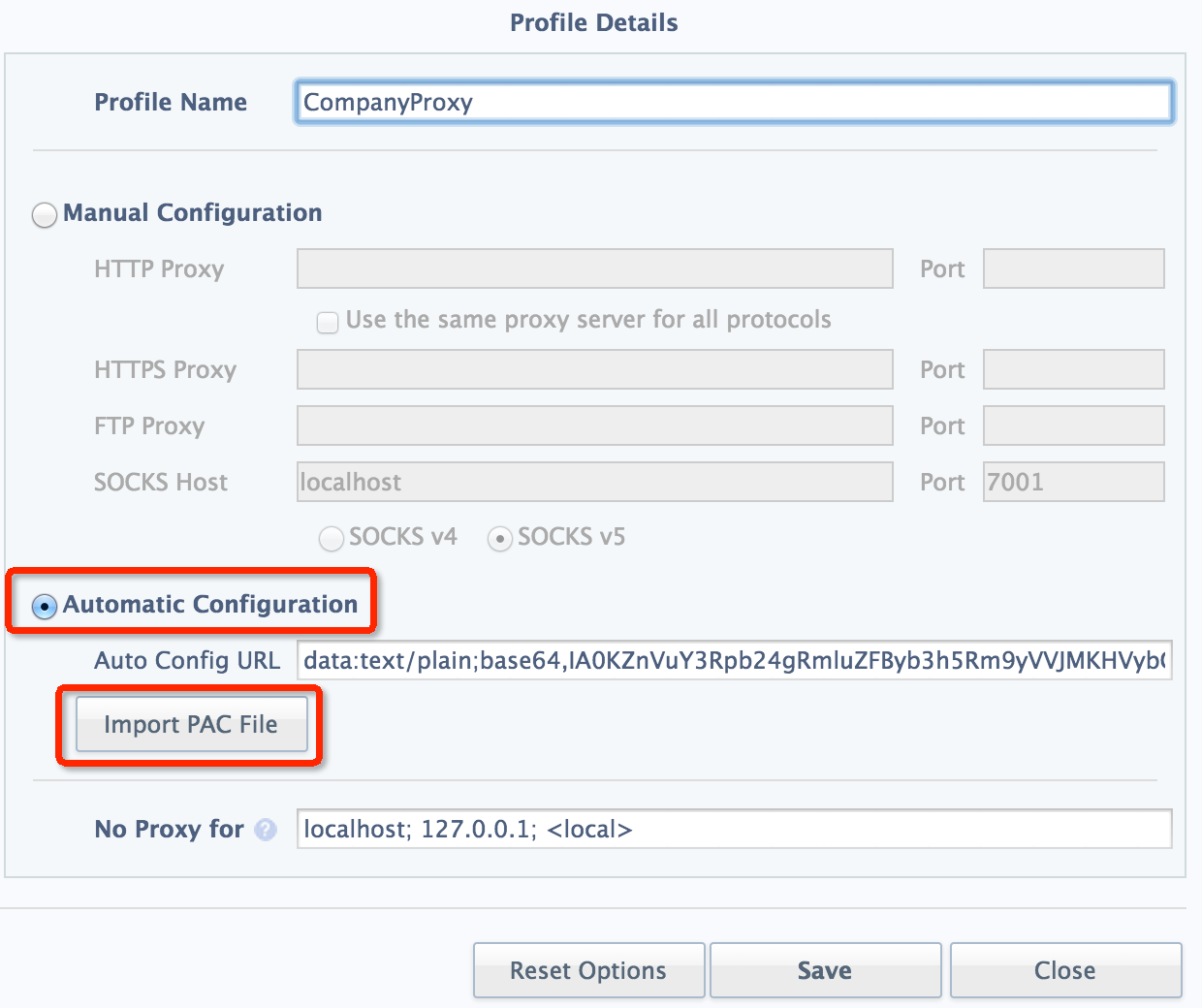
If this proxy is set on another node rather than localhost, we have to add '-g' parameter, which is well-explained in document: "Allows remote hosts to connect to local forwarded ports", to accept external IP other than mere localhost.
ssh -g -D 7001 supertool@644v3.hide.cn
References:
- the-beginners-guide-to-iptables-the-linux-firewall
- 25 Most Frequently Used Linux IPTables Rules Examples
- Configuring iptables - HortonWorks
- SSH Forward - IBM
- SSH Port Forwarding
- pac-functions
© 2014-2017 jason4zhu.blogspot.com All Rights Reserved
If transfering, please annotate the origin: Jason4Zhu
nice post
ReplyDeleteivanka trump hot pictures