There are three types of SQL operation:
1. Take values from a single row as input, and generate a single return value for every input row
A lot of built-in functions or UDFs such as
substr or round belongs to this scenario. It is a one-to-one mapping procedure.
A typical SQL would look like:
select
userid,
score+20 -- one-to-one mapping (score) to (score+20)
from result
2. Aggregate on a group of rows and calculate a single return value for every group
Applying aggregation function like
sum, count, avg after group by syntax.select
userid,
sum(score)
from result
group by userid
3. Operate on a group of rows, and return a single value for every input row
The difference between scenario 2 and 3 is that, scenario 2 will merge a group of values into one row of value, group is exclusive between each other; whereas scenario 3 will have a sliding window of values to cooperate with each row and return a row of value for each row.
which is illustrated as below:
Examplary data:
| userid | score |
|---|---|
| 1 | 1 |
| 1 | 3 |
| 1 | 15 |
| 1 | 7 |
| 2 | 4 |
| 2 | 1 |
| 2 | 16 |
Scenario 2:
select
userid,
sum(score)
from result
group by userid
After
sum(score) and group by userid operation, each user's rows (in each group) will be aggregated into one and only one line:| userid | score |
|---|---|
| 1 | 19 (1+3+15) |
| 2 | 21 (4+1+16) |
Scenario 3:
Calcluate the score difference between current score and the lowest score of each user:
select
userid,
score,
(score - min(score) over (partition by userid order by score asc rows between unbounded preceding and current row)) as score_diff
from results
In the above example, we apply
window function in SparkSQL to iterate through every score and all preceding scores in each user. The format is as follows:OVER (PARTITION BY x ORDER BY y frame_type BETWEEN start AND end)
partition by xwill separate data into multiple partitions according to column x, and the window will be in range of each partition.order by ywill order each partition according to column y, this merely sorts the rows in current window, without changing the size of window.frame_typehas two values, namely,ROWSandRANGE, which stands for ROW frame and RANGE frame respectively.- ROW frames are based on physical offsets from the position of the current input row, which means that
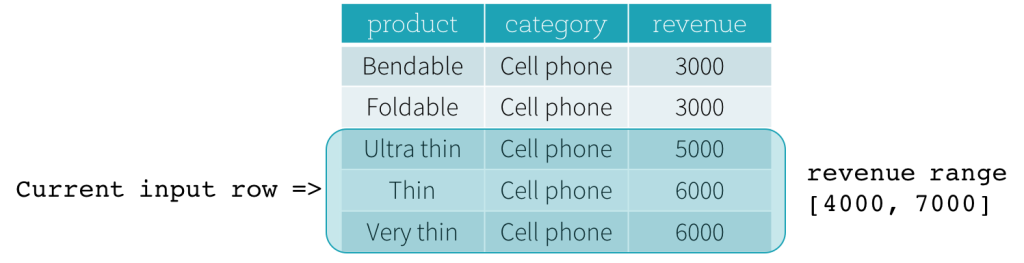
CURRENT ROW,<value> PRECEDING, or<value> FOLLOWINGspecifies a physical offset. IfCURRENT ROWis used as a boundary, it represents the current input row.<value> PRECEDINGand<value> FOLLOWINGdescribes the number of rows appear before and after the current input row, respectively. The following figure illustrates a ROW frame with a1 PRECEDINGas the start boundary and1 FOLLOWINGas the end boundary (ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWINGin the SQL syntax).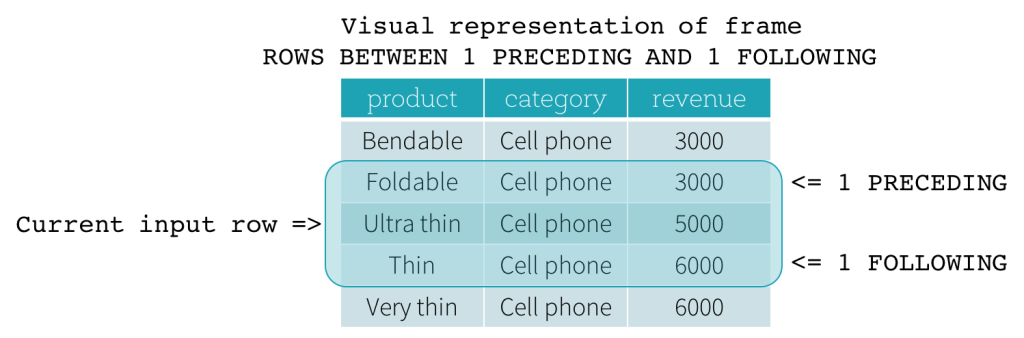
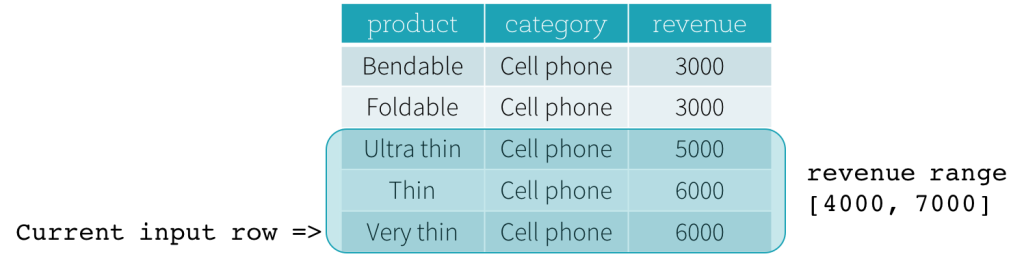
- RANGE frames are based on logical offsets from the position of the current input row, and have similar syntax to the ROW frame. A logical offset is the difference between the value of the ordering expression of the current input row and the value of that same expression of the boundary row of the frame. Because of this definition, when a RANGE frame is used, only a single ordering expression is allowed. Also, for a RANGE frame, all rows having the same value of the ordering expression with the current input row are considered as same row as far as the boundary calculation is concerned.
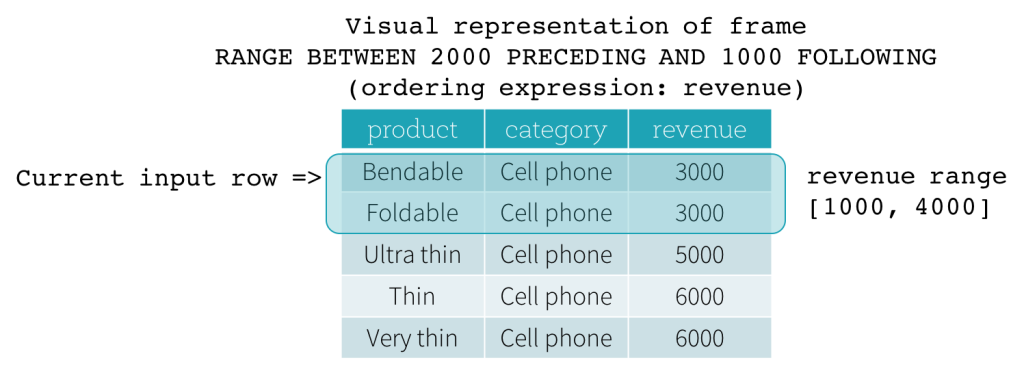
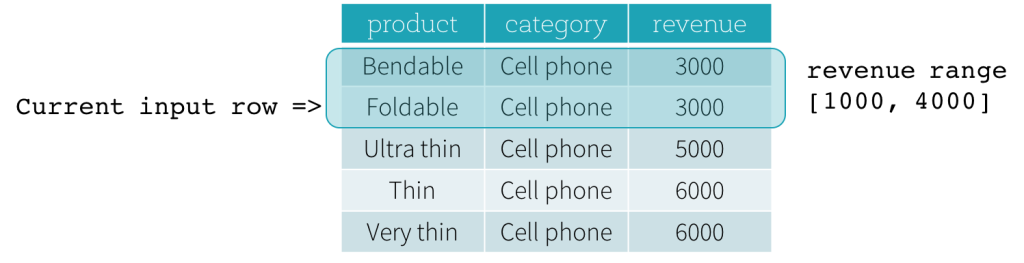
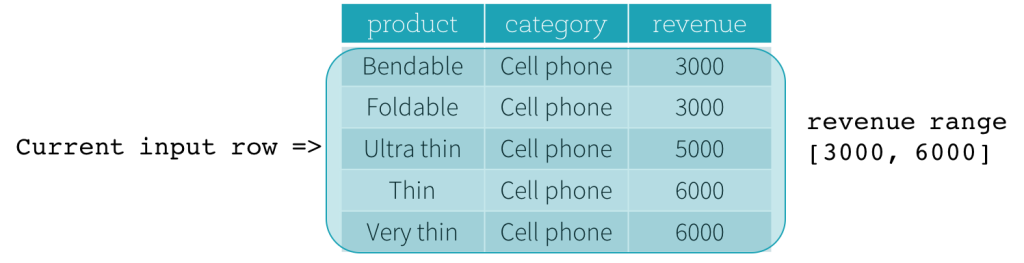
startandendcould beUNBOUNDED PRECEDING,UNBOUNDED FOLLOWING,CURRENT ROW,<value> PRECEDING, and<value> FOLLOWING.UNBOUNDED PRECEDINGandUNBOUNDED FOLLOWINGrepresent the first row of the partition and the last row of the partition, respectively.- For the other three types of boundaries, they specify the offset from the position of the current input row and their specific meanings are defined based on the type of the frame illustrated above.
Actually, the default value for
frame_type, start and end is ROWS, UNBOUNDED PRECEDING and CURRENT ROW respectively. So the example in scenario 3 could be simplified to:select
userid,
score,
(score - min(score) over (partition by userid order by score)) as score_diff
from results
which is also the same as all following SQLs:
select
userid,
score,
(max(score) over (partition by userid order by score asc rows between current row and unbounded following) - score) as score_diff
from results
select
userid,
score,
(max(score) over (partition by userid order by score desc) - score) as score_diff
from results
3.1 A Practical Use Case for Window Function - 1
For data below, we intend to cut each user's event flow into multiple sessions via adjacent time difference. If time difference is above 10, it's deemed to belong to two different sessions. For illustration, the data is represented in sorted order by column
ts, which is not required in real use case.| userid | ts |
|---|---|
| 1 | 1 |
| 1 | 3 |
| 1 | 7 |
| 1 | 21 |
| 1 | 25 |
| 1 | 40 |
| 2 | 1 |
| 2 | 7 |
| 2 | 27 |
| 2 | 29 |
Firstly, we'll apply window function to calculate time difference between adjacent events in pair:
select
userid,
ts,
(ts - lag(ts, 1) over (partition by userid order by ts)) as ts_diff
from event_flow
This will generate temporary table as below:
| userid | ts | ts_diff |
|---|---|---|
| 1 | 1 | None |
| 1 | 3 | 2 |
| 1 | 7 | 4 |
| 1 | 21 | 14 |
| 1 | 25 | 4 |
| 1 | 40 | 15 |
| 2 | 1 | None |
| 2 | 7 | 6 |
| 2 | 27 | 20 |
| 2 | 29 | 2 |
Then we could apply another round of window function to mark each row with its corresponding session number:
select
userid,
ts,
ts_diff,
(sum(case when diff >= 10 then 1 else 0) over (partition by userid order by ts)) as session_number
from
(
select
userid,
ts,
(ts - lag(ts, 1) over (partition by userid order by ts)) as ts_diff
from event_flow
) tmp
Eventually, we will have a temporary table like below:
| userid | ts | ts_diff | session_number |
|---|---|---|---|
| 1 | 1 | None | 0 |
| 1 | 3 | 2 | 0 |
| 1 | 7 | 4 | 0 |
| 1 | 21 | 14 | 1 |
| 1 | 25 | 4 | 1 |
| 1 | 40 | 15 | 2 |
| 2 | 1 | None | 0 |
| 2 | 7 | 6 | 0 |
| 2 | 27 | 20 | 1 |
| 2 | 29 | 2 | 1 |
3.2 A Practical Use Case for Window Function - 2
Retrieve Top N in each group. We still use the examplary data in scenario 2:
| userid | score |
|---|---|
| 1 | 1 |
| 1 | 3 |
| 1 | 15 |
| 1 | 7 |
| 2 | 4 |
| 2 | 1 |
| 2 | 16 |
what we expect is to retrieve the top 2 highest score for each user.
Firstly, we assign row number to each user's rows ordering by score descedently:
select
userid,
score,
(row_number() over (partition by userid order by score desc)) as rank
from results
Then we simply retrieve all rows with rank <= 2:
select
userid,
score
from
(
select
userid,
score,
(row_number() over (partition by userid order by score desc)) as rank
from results
) tmp
where rank <= 2
The result will be:
| userid | score |
|---|---|
| 1 | 15 |
| 1 | 7 |
| 2 | 16 |
| 2 | 4 |
3.3 A hack for window function in MySQL
Data sample:
| userid | dt | type |
|---|---|---|
| u1 | 2 | 3 |
| u1 | 5 | 4 |
| u2 | 4 | 3 |
| u2 | 10 | 4 |
If we intend to group by
userid, substract dt from type 4 to type 3, so the result shoudl be:| userid | diff |
|---|---|
| u1 | 3 |
| u2 | 6 |
This could be hacked by the following SQL:
select
userid,
(t4.dt - t3.dt) as diff
from t t3
join t t4
on t.userid = t4.userid and t4.type = 4
where t.type = 3
3.4 Window Function VS Self-Join
Extend later from this post
After reading this blog i very strong in this topicsBig data hadoop online Course
ReplyDelete